Autonomous Driving Simulation
Due date: Dec 7th, 2017
Group member: Zezhou Sun, Siqi Zhang
Project Overview
Developing a robust autonomous driving system for automobile is always a popular topic in the field of computer vision and artificial intelligence. In this project, our team will take on the task of creating an autonomous driving system for a car racing simulation game with the help of feature extraction algorithms as well as the deep learning models.
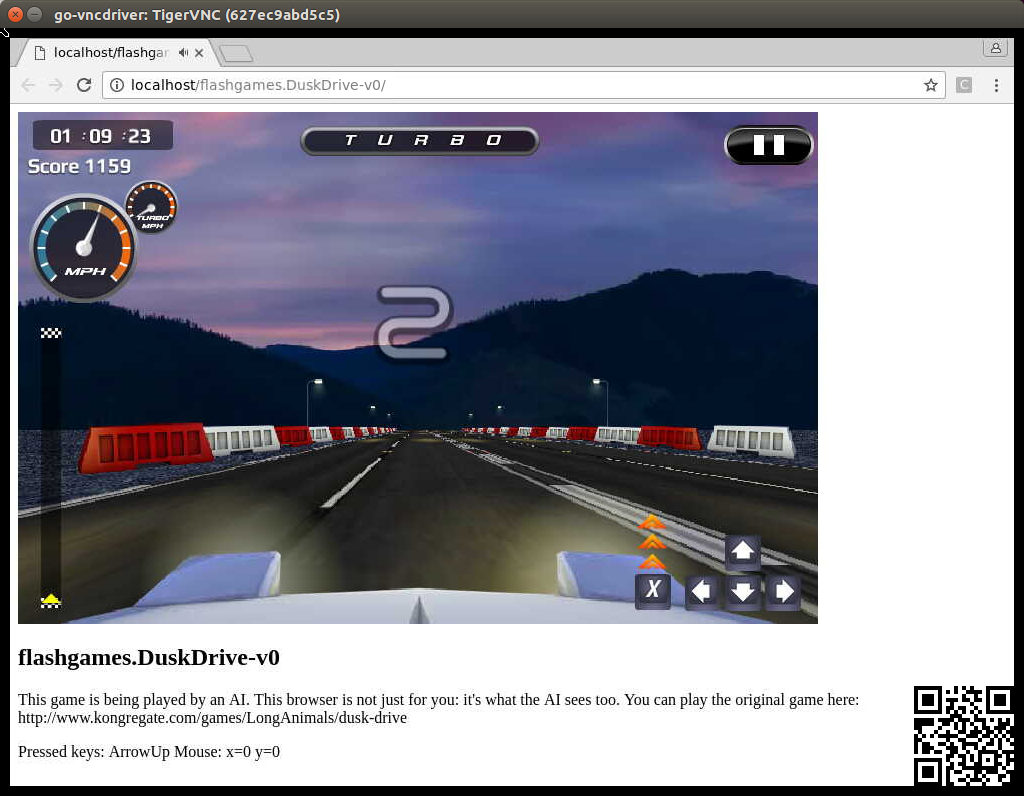
Figure at right shows one frame sample of the game.
Figure 1. Game UI
Problem Definitions
Problem Analysis
It is necessary to preprocess the images before feeding them into the model due to several of noises. Figure 2 shows that the brightness of the road can vary because of the illumination from the headlights and streetlights. And Figure 3 is the case that the brightness can also be affected by random fog on the road surface.
Figure 2. Multiple illumination sources Figure 3. Fog
Besides the brightness invariance, the background could be problematic. Figure 4 demonstrates noise brought by background. It will be helpful for DQN model training If we can subtract the background because it will reduce number of states for analysis. But the perspective view is always changing, which makes it inappropriate to use a certain line to cut image to get road from frame image. Figure 5 and 6 shows the case where the horizontal lines of road are quite different on every frame. So we need a well designed algorithm to cut road out of frame.
Figure 4. Background noise Figure 5. Driving uphill Figure 6. Driving downhill
System Architecture
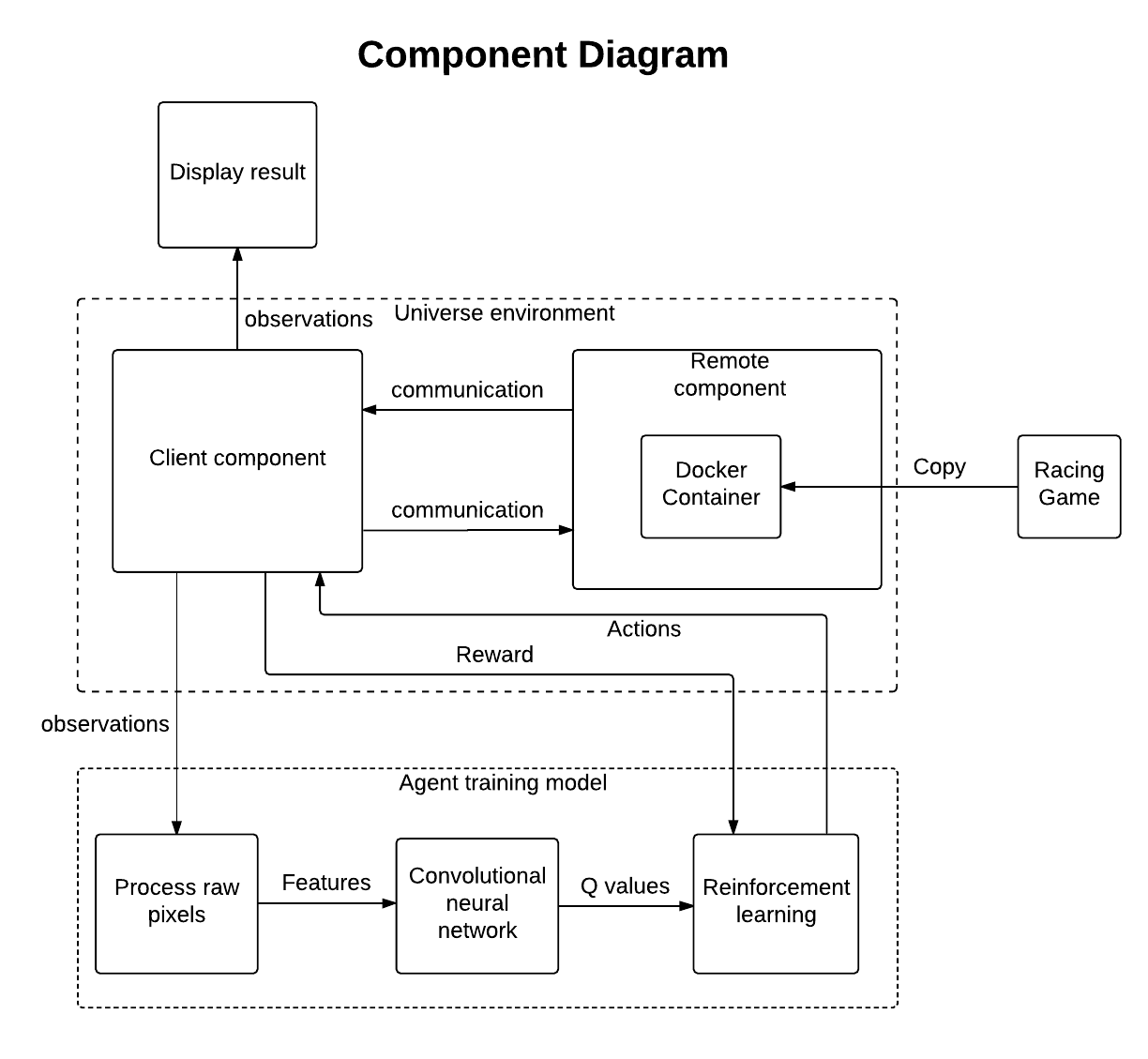
There are two major parts in our system: Universe[1] Environment and Agent Training Model.
Figure 7. Universe environment
Then we initialize the parameters for learning model and start the iterative process. The learning process can be described by the following pseudo code and diagram.
Environment and variable Initialization
While episode_n < max_episode
state = None
Next_state = None
Feed rewards and observations to model
Model process next_state
Record event (state, next_state, reward)
state=next_state
Forward state in neural network
Agent take action(s) based on NN output
Environment receives the action(s)
Model update DQN based on events
End of while
Save learning model
Diagram 1. Component Diagram
Algorithms Details
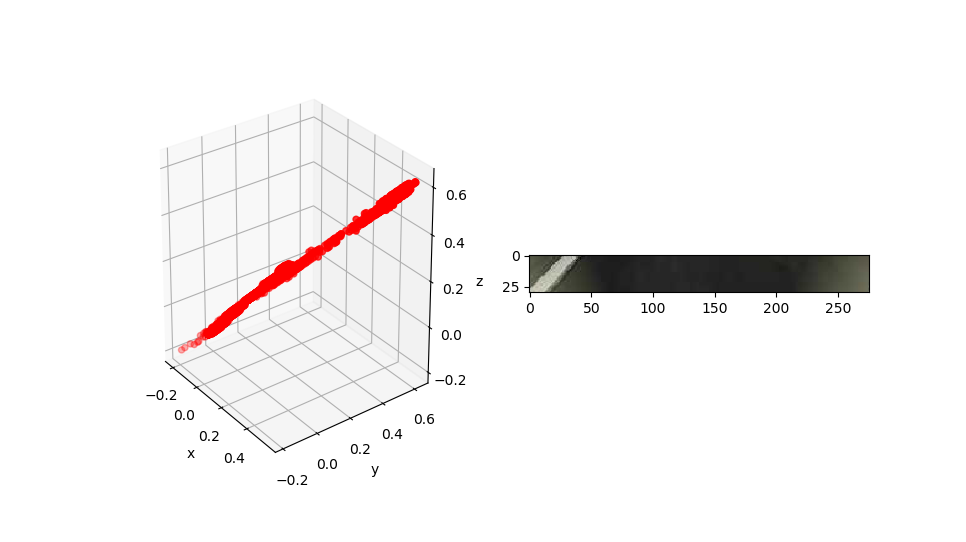
After analysis of image pixels, we found the road pixels’ rgb follows regression 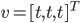 . Thus we can calculate distance from every pixel to this regression line, and set a threshold, if distance smaller than threshold, then this pixel belongs to road. The formula to calculate this distance is:
. Thus we can calculate distance from every pixel to this regression line, and set a threshold, if distance smaller than threshold, then this pixel belongs to road. The formula to calculate this distance is:
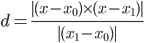
Where 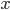 is the pixel’s rgb coordinate. And
is the pixel’s rgb coordinate. And 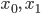 are two points on regression line. In the implementation of this algorithm, we use
are two points on regression line. In the implementation of this algorithm, we use 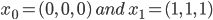 for simplification. And symbol
for simplification. And symbol 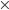 represent cross product of two vector.
represent cross product of two vector.
And we set threshold as 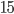 . For pixel with
. For pixel with 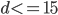 , we say pixel belongs to road.
, we say pixel belongs to road.
Then apply dilation and erosion on output binary image. Here is an example of road segmentation result.
Figure 8. Pixel Regression Line Figure 9. Road Segmentation
Furthermore, we tried several feature representations for the processed image and we will have a combination of them as part of the input for Neural Networks. Figure on left shows the result of applying adaptive thresholding with morphology. Middle Figure shows the result of using Canny edge detection. Right Figure shows the result of Scale-invariant Feature Transform(SIFT).
Figure 10. Thresholding + morphology Figure 11. Canny Figure 12. SIFT
Only current frame is not enough for DQN to make judgement what current direction and speed is, so we need to send neural network more history frames. We concatenate rgb channels with 4 history canny edge detection results and 1 road segmentation through axis 2, so we finally get output in format Height*Width*Channels=512*800*8. And we apply resize on every channel to reduce output size, then we get final output 64*100*8.
Eventually, we had to give up the adaptive thresholding and SIFT based on the
following considerations:
After resize and concatenate of image, the final input have shape 64*100*8. In which 8 channels consist of 3 rgb channels, 4 history canny edge detections and 1 road segmentation.
We construct our Neural Networks based on the paper published by DeepMind Technologies and Pytorch tutorial, with some modifications. Table 1 shows the detailed settings for our Neural Networks.
Table 1. Neural Networks Architecture
Type | # of class/filter | Class/filter size | Stride | Activation |
Conv-1 | 16 | 3 x 3 | 2 | ReLU |
Conv-2 | 32 | 4 x 4 | 2 | ReLU |
Conv-3 | 64 | 5 x 5 | 2 | ReLU |
FC-1 | 300 | 3200 x 300 | N/A | ReLU |
FC-2 | # of Actions | 300 x #of Actions | N/A | Linear |
There are totally 8 possible actions to take, but considering long training time and limited time left for this project, we only take 3 actions (UP, UP+LEFT, UP+RIGHT) which involve forward moving for training.
Given a state input, network should output scores for each action. Since we are using 3 actions at here, network should output 3 scores. Then we can apply some algorithm to make decision which action to take based on these scores. In this model, we actually take max score’s corresponded action as final action to take.
The deep reinforcement learning uses a Neural Network to approximate function which take state as input and return score for every actions for decision make. The value for that action is actually the expected sum of discount rewards that we can get if we select to take this action under current state. Every time we make a decision on action to take, we record current state and action we take, also the next-state (we can get this when next state input into our model) as an event. Then we push this event to experience pool[10]. Then we randomly select events from experience pool and update DQN using these events. Based on bellman equation, the target Q value for state s and action a is
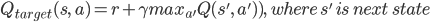
Then we update current Q(s, a)
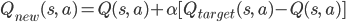
Then we use current  and
and  to define loss function for back propagation.
to define loss function for back propagation.
At here we use smooth_l1_loss as loss function, which is defined as following[7][11]:
{ 0.5 * (x_i - y_i)^2, if |x_i - y_i| < 1
loss(x, y) = 1/n \sum {
{ |x_i - y_i| - 0.5, otherwise
To explore the solution space as much as possible, we use epsilon-greedy[10] algorithm for action selection, that is:
Define a epsilon which is in (0, 1) and will decay with time, take a random number in (0, 1). If this random number if larger than epsilon, we use the action select by the network as action we are going to take. Otherwise we randomly take an action. After a long period of training, the epsilon will be very small and most action will be selected by DQN.
To reach our goal, we need to define a good reward which can reflect the quality of current state. After many test, we combined following 3 partial rewards as final reward. And the final rewards is defined as
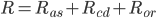
The average of score changes during this observation. This can reflect if the car is driving in a good condition. We want the program to drive the car as fast and as smooth as possible, so this is very important. But we just find the score distributed on a large range, which brings difficulty for us to use this directly. So we use log function to smooth it. The reward of this part is defined as following:
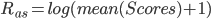
Because we can only get score changes during a short time. And we can use this to do crash detection. Because score changes represent distance the car moved between last frame and current frame. So according to the physical definition 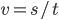
Score changes actually reflect average speed during this short period. And if we calculate derivative of v to t, we get 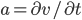 which is the acceleration of the car.
which is the acceleration of the car.
If the car move in constant velocity or accelerate, a should greater or equal to 0. Otherwise a should be smaller than 0. If a is smaller than 0, that means there must be something happened caused speed decrease. At here we make a simple assumption that crash is the main reason that cause the decrease of car speed. So to calculate the acceleration of this, we only need to calculate changes of score changes, notate it as ac. Then we define reward for crash detection as following:
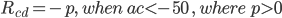
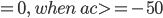
This reward is actually based on a manually defined rule: Car should drive on road. When car run off the road, we will give the model a little penalty. But to detect if the car has run off the road is another big problem. Because we can only get images and scores from environment, we have no idea what happened inside the program. So we can only use what we have to design such rewards. Just like we mentioned above, we use the same method as road segmentation to do this. First we cut a small area in front of the car for detection. Then apply road pixel judgement on it. For this block, if there are more than 20 percent pixels don’t belong to road, we can say car has run off the road. Here is the confusion matrix for this method. A whole episode ran for test.
Table 2. Confusion Matrix
Label: Car off road | Label: Car on road | |
Algorithm: Car off road | 103 | 19 |
Algorithm: Car on road | 4 | 125 |
False positive rate of this algorithm 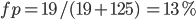
True positive rate of this algorithm 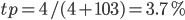
Accuracy of this 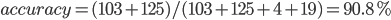
Because we only want to punish the model when car run off road and also run at a low speed, so true positive rate is more important to us. Then this algorithm can actually works well. And we define the reward for crash detection as following:
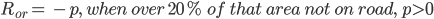
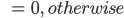
Experiment and Future Work
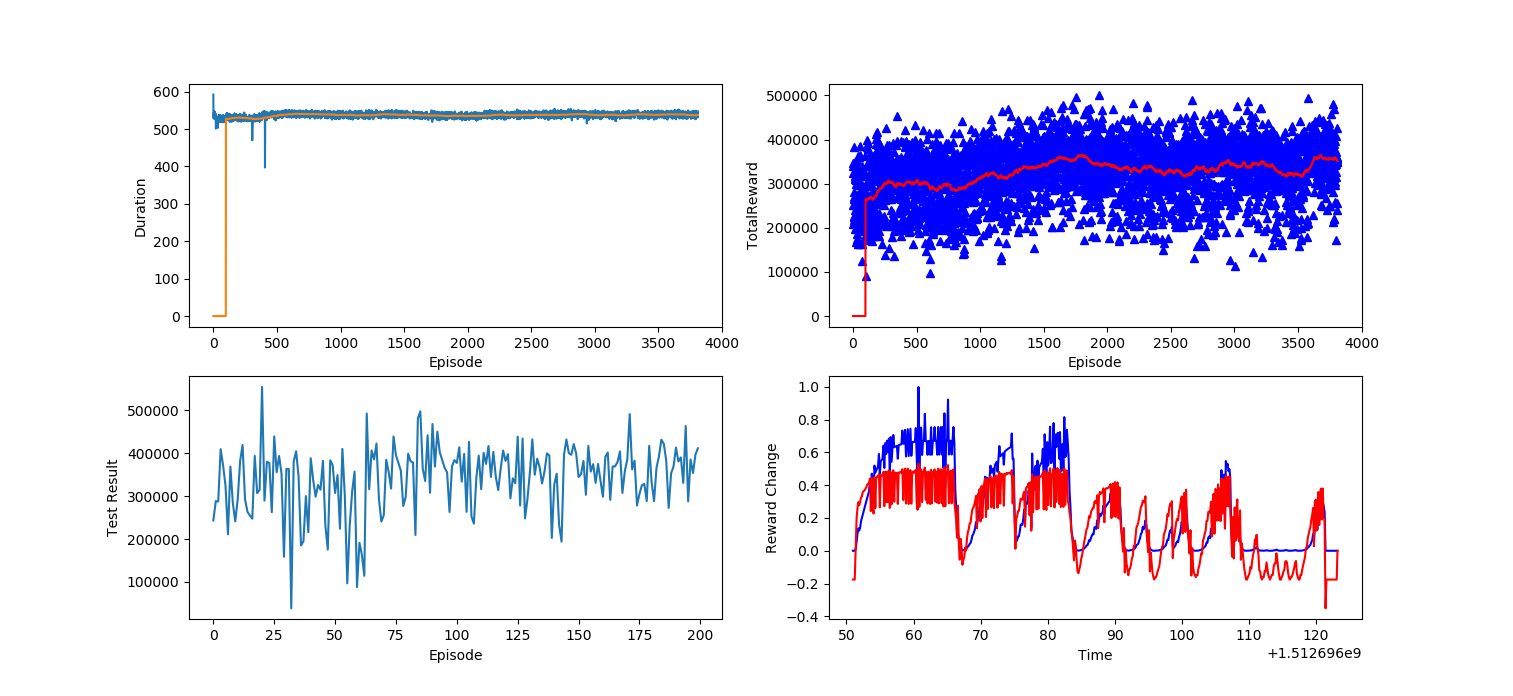
We don’t have much time for training, and current training result showed below. Left figure is the result that test result changes with time. Test is totally depend on DQN action selection, no random action selection will take place. We can see the longer we train, the less bad test scores we get.
Right figure shows total score changes with training episode. We can see a increasing trend of it.
Figure 13. Test result changes Figure 14. Total Reward changes
We post a video on youtube which shows our agent’s training result. https://youtu.be/qcY6T6Hn0jE.
We developed this model based on [9] and [11]. We tried to apply their model on this game, but it don’t work. Actually the longer we train it, the worse it performance. So we implement current method. As a result, we are able to get an acceptable result: after 3800 episodes of training, the agent is able to gain a score over 450K and a race completion above 85%. At current stage, the agent is able to dodge some cars when driving along straight lane. It is also able to steer when it’s need. However there are certain critical cases that it has not yet learned the optimal action:
Although our current agent is not able to gain 100% completion for the race, we are hopeful that it will achieve the goal. There are a few things we would like to try in the near future:
Conclusion
Throughout the project, we realized appropriate pre-processing method play an important role in image processing, and also learned how to use some of the methods we learned in this semester to facilitate the machine learning. We have experienced how powerful reinforcement learning is and how much it is able to do. The most amazing thing we have learned is that reinforcement learning can work within an environment without having any presumptions if the state and reward is well designed(i.e.Our model can work with any car racing game, though performance will vary): it gets in the environment without any knowledge of it and learns about it by trying -- This is exactly how we human learn things.
References
<https://arxiv.org/pdf/1312.5602v1.pdf> Accessed on Nov 5th 2017
<http://pytorch.org/tutorials/intermediate/reinforcement_q_learning.html>